SM.MS是个不错的图床工具,上传的图片资源虽然不能批量一键下载,但官方还是提供了一个获取图片列表的API:https://sm.ms/api/v2/upload_history,header中只需要提供一个Authorization认证码即可,好长时间没写python了,想练练手,就不用API了
之前爬取需要登陆的网站我都是通过Selenium完成,尝试换个姿势,通过requests.Session实现?首先分析下SM.MS网站的登陆流程: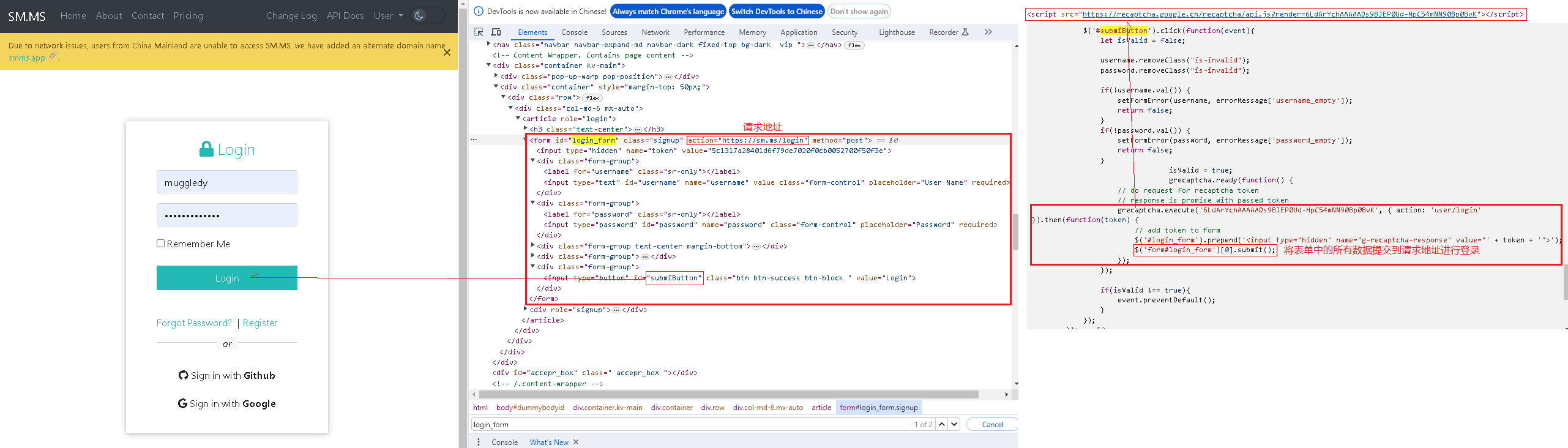
使用fiddler抓包查看表单请求内容: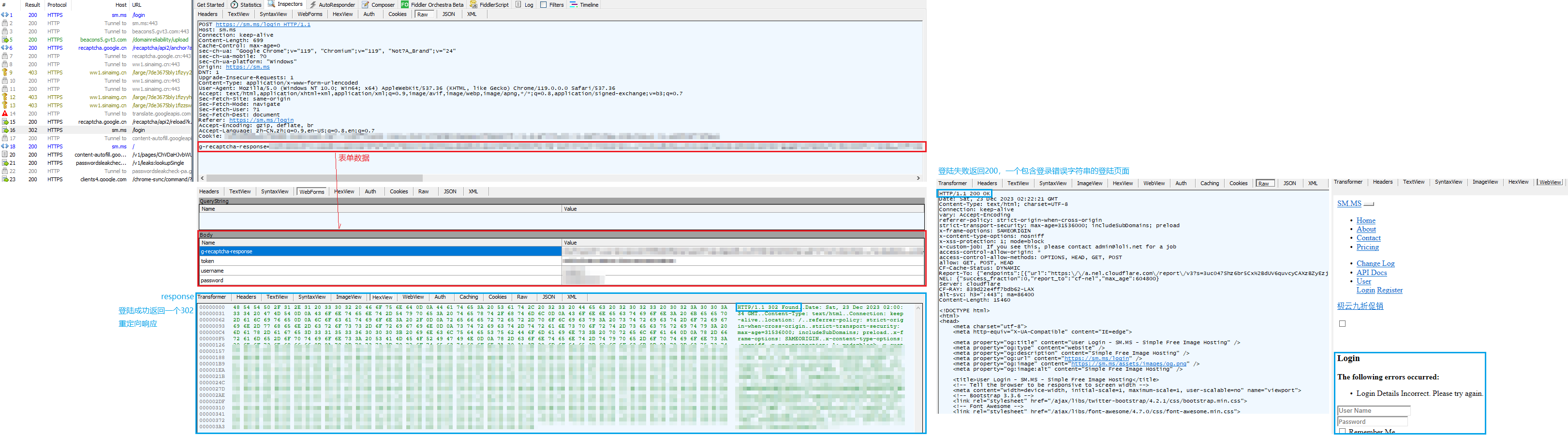
唯一的障碍点其实就是g-recaptcha-response字段值的获取(我本想通过execjs模块执行JS代码),sm.ms通过<script src="https://recaptcha.google.cn/recaptcha/api.js?render=6LdArYchAAAAADs9BJEP0Ud-MpC54mNN90Bp0BvK"></script>获得了一个grecaptcha对象,然后调用grecaptcha.execute()得到了g-recaptcha-response字段值,然而execjs主要是一个在非浏览器环境中执行JS代码的工具,因此涉及到浏览器特有对象(如window、document)的代码在这个环境下通常是无法正常工作的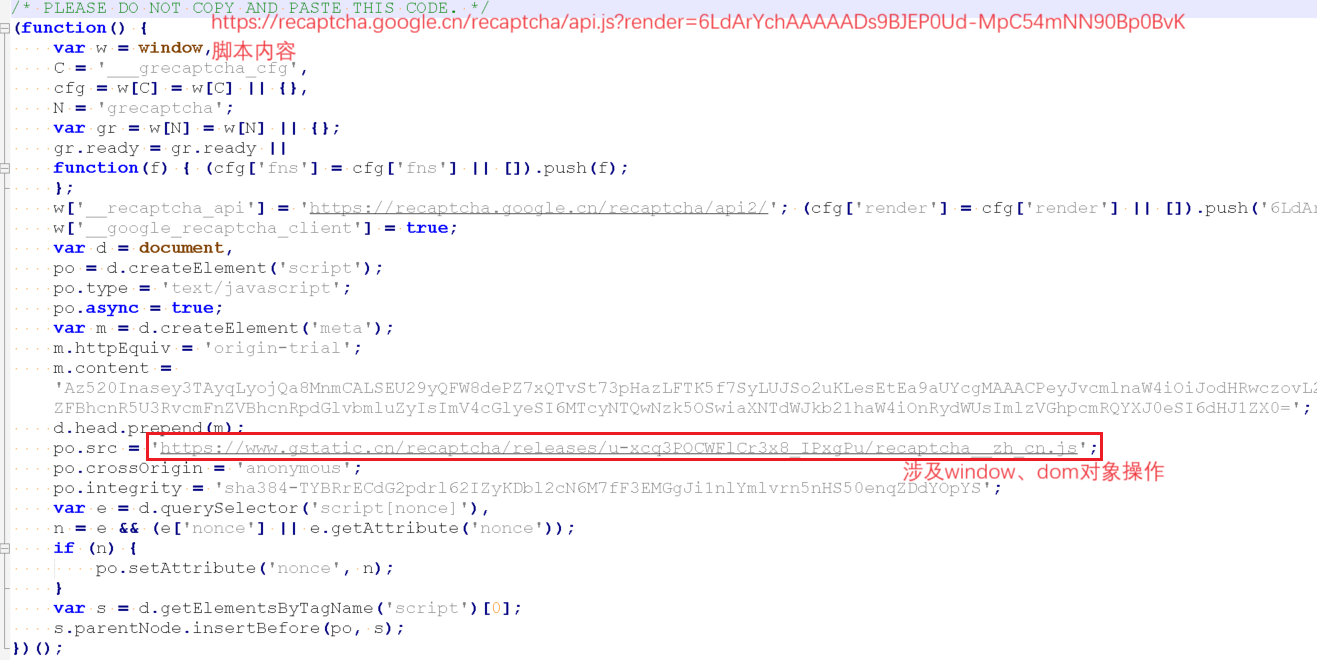
好吧,姿势更换失败,还是只能通过selenium(+chrome)爬取SM.MS图片数据了,但是为了尽量寻求较优的实现方案,我只会用selenium完成登陆操作,之后就可以拿到网站cookie,再用requests库携cookie请求个人图片资源列表、下载图片数据,毕竟如果是做大规模图片爬取的话,使用selenium速度实在太慢了,肯定得用并发URL请求下载资源,而且很多境外服务器一次网络请求都有可能是以秒为单位,单线程下载不得等到地老天荒啊,对于python来说,爬虫属于网络IO密集型任务,因此直接用线程模块即可或者上线程池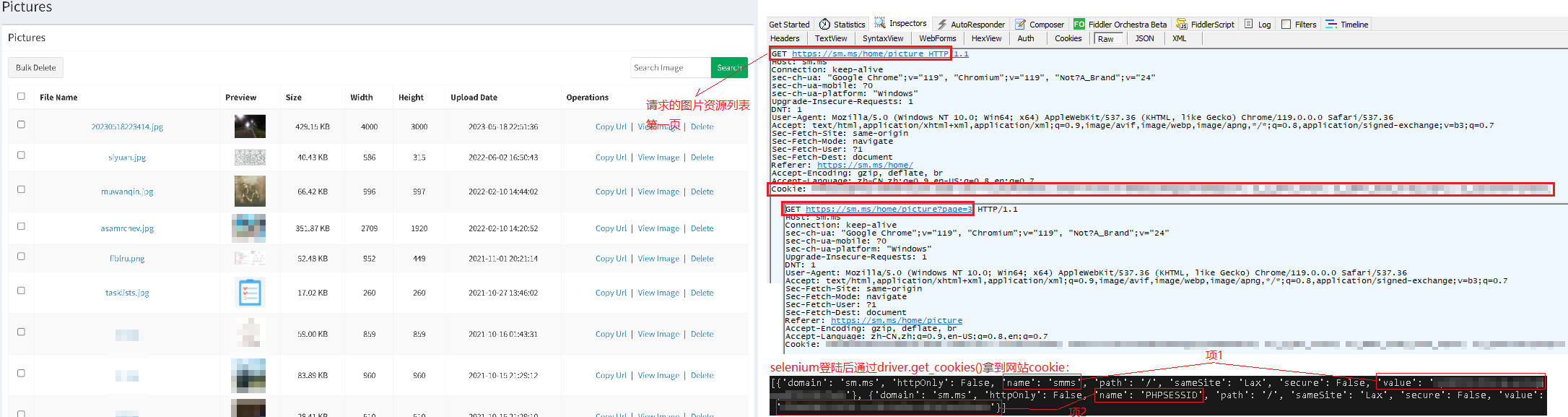
其实要确定请求头参数有个更好的办法,直接F12找到网络请求链接右键Copy as cURL(还可以顺便cmd执行一下看看能否成功):
1 | curl "https://sm.ms/home/picture" ^ |
执行request.get(url, cookie)报错:OpenSSL.SSL.Error: [(‘SSL routines’, ‘ssl3_get_server_certificate’, ‘certificate verify failed’)],意思是对于sm.ms服务器发过来的证书验证失败了,解决办法就是在get方法中传递verify参数以指定用于验证的CA根证书,从sm.ms网站下载用于验证的根证书(链),crt格式,然后用XCA转换为单个pem格式证书: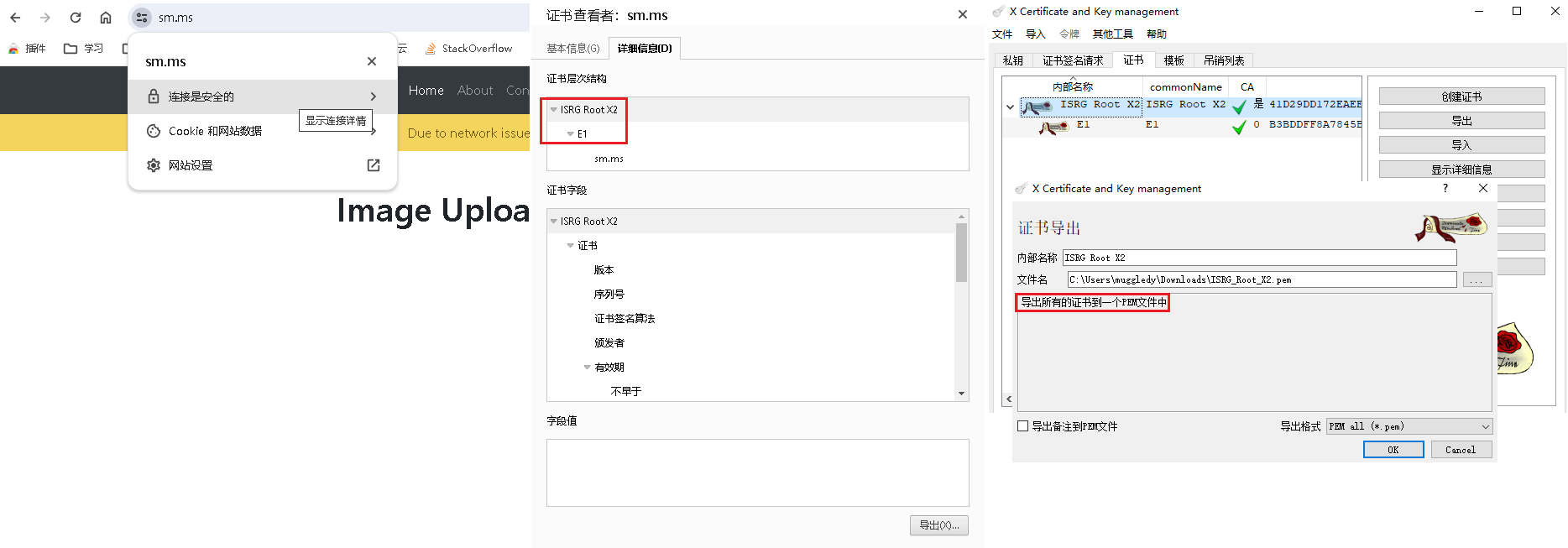
获取到所有图片资源的URL列表,就可以通过get请求下载二进制图片了,经过一系列操作,我得到了一个用字典构建的图片数据库db,其键值对定义如下:<img_unique_key : [img_name, url, size, upload_date, download_flag, local_path]>,其中download_flag指示其是否已被下载到本地,只有为否的图片url才需要提交给线程池通过request执行下载,local_path是图片的本地下载路径。通过线程池下载实现:
1 | urls = {k:v[1] for k,v in db.items() if v[-2]==False} #find all pictures not downloaded |
最后我又将图片数据库db导出为一个简易html页面:
完整代码见github仓库smms_download,支持增量更新





