程序结构与执行
Python程序由一些语句序列组成,这些语句包括变量赋值、函数定义、类和模块导入等,加载源文件时,解释器始终顺序执行每条语句,直到再无语句可以执行,这种执行模式同样适用于作为主程序运行的文件和通过import加载的库文件
条件语句可由if以及可省的elif、else子句构成
在一些编程语言中存在switch语句,譬如C语言中实现成绩等级判断:
1 |
|
Python中没有switch关键字,可以通过以下方式替代实现:
- 利用字典实现:
1
2
3
4
5
6
7
8
9switch={
10: 'A', #此处需重复定义内容
9: 'A',
8: 'B',
7: 'C',
}
a=input('Input your score:')
print(switch.get(int(int(a)/10),'D')) - 创建一个
switch类来处理程序的流转:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32class switch:
def __init__(self,value):
self.value=value
self.fall=False #如果case匹配,且没有break,则置为True,表示继续向下执行,且不论下面的case是否匹配
def __iter__(self):
yield self.match #由于yield关键字,__iter__()方法变成一个生成器方法,当调用该方法时将返回一个生成器对象(而生成器又是迭代器,因此switch类实例是一个可迭代对象),此时__iter__()内部实际还未执行,直到调用生成器对象的__next__()方法,返回match函数对象
def match(self,*args): #args只允许接收0或1个参数
if self.fall or not args: #如果fall为True,则返回True表示继续执行当前的case子句,或当前case子句没有匹配参数,则表示为default默认分支(请将default放在最后一行,但并无代码严格检查,此代码仅为demo展示)
return True
elif args[0]==self.value: #匹配成功
self.fall=True
return True
else: #匹配失败
return False
score=96
for case in switch(score//10): #这个for只迭代一次,case循环变量指向的就是match()函数对象
if case(10):
pass
if case(9):
print('A')
break
if case(8):
print('B')
break
if case(7):
print('C')
break
if case(): #default分支
print('D')
不过实在没必要,特别是上述第二种方式,过于词不达意,这种for循环的写法就很迷,但是好像也找不到更好的写法
可以使用while(满足条件时不断循环直至条件不再满足)或for(遍历可迭代对象)实现循环,一般推荐使用for循环,如果想在迭代过程中同时获取下标索引,可以将可迭代对象iterable替换成enumerate(iterable),其等同于zip(range(len(iterable)),iterable)
1 | a=10 |
注(for-else语句):else语句会在for循环结束之后执行,除非循环过程中遇到break(或者遇到其他意外如抛出异常,当然也不会执行到else语句),特别地,如果循环根本就没有开始(可迭代序列长度为0时),也会执行else语句,一般来说,else语句可以用于编写循环正常结束时的某些后续操作
1 | for i in range(4): |
异常会中断正常的程序执行流,可以使用raise exception([value])来手动抛出异常(exception是异常类型,内置异常类型请查阅文献[1]-p70,value是一个与指定异常相关的可选参数,通常是一条自定义的错误消息,如果raise语句不带任何参数,则将会重复引发最近一次出现的异常,如果最近没有出现异常,则抛出运行时异常RuntimeError: No active exception to reraise),使用try-except(能够嵌套使用)可以捕捉异常,except语句中用于编写异常处理程序,其还有一个可选的修饰符as var,可以将捕捉到的异常实例赋给变量var,另外可以在一个try块后跟随多个except块以捕捉多种不同类型的异常,当然也可以在一个except中同时捕捉,这时你可以在except语句块内使用isinstance进行异常类型判断,示例:
1 | #示例1 |
try-except支持else子句(可省),但必须跟随在最后一个except子句后,如果try块中的内容并未引发异常,就会执行else子句中的代码(除非try块直接return返回了)。try-except还支持finally子句(可省),其必须写在最最后,无论try是否出现异常都会执行finally块中的内容(即使在try块、except块或else块中遇到return,也会执行finally块),且在except或else之后执行
1 | try: |
关于异常捕捉中return返回值的问题,试想,如果try块中存在return语句,通常我们认为函数遇到return会立即返回,确实如此吗?如果存在finally块,那么其中的代码还会执行吗?具体看下面的例子:
1 | #try-except-finally结构 |
要自定义异常类型,需继承Exception基类,引发异常时传递的参数即是__init__()构造函数的参数,可以重载__str__()方法,以自定义异常输出的错误消息,示例:
1 | class myException(Exception): |
正确地管理各种资源(如文件句柄的获取与关闭、互斥锁的获取与释放和数据库的连接与断开等),在涉及异常时通常都比较棘手,异常的引发很可能导致控制流跳过负责释放某些关键资源的语句,with语句支持在由上下文管理器对象控制的运行时上下文中执行一系列语句,譬如:
1 | #此种写法可以确保文件资源被安全释放 |
with obj语句在控制流进入和离开其后的相关代码块时,允许(上下文管理器)对象obj管理所发生的的事情,执行with obj语句时,将执行obj.__enter__()来指示进入一个新的上下文,当控制流离开该上下文时,就会执行obj.__exit__(type,value,traceback),如果没有引发异常,__exit__()方法的三个参数均被设为None,否则,它们将包含导致控制流离开上下文的异常相关的类型、值和跟踪信息,__exit__()方法返回True或False,用于指示被引发的异常是否得到处理,如果返回False,引发的任何异常都将被继续向外抛出。with obj语句接受一个可选的as var修饰符,此时obj.__enter__()方法的返回值将被赋给变量var
自定义一个上下文管理器的伪代码示例如下:
1 | class contextor: #类实现的“上下文管理器” |
还有一种定义上下文管理器的方式,借助contextlib模块的contextmanager装饰器实现,伪代码示例如下:
1 | from contextlib import contextmanager |
contextmanager装饰器的原理很简单,其实现依赖于一个名为_GeneratorContextManager的类,这是一个定义了__enter__()和__exit__()方法的上下文管理器类型,而被装饰的函数contextor是一个生成器函数,根据装饰器原理有contextor=contextmanager(contextor),返回的是一个闭包函数对象,其包含有一个指向真实contextor函数地址的变量,姑且记作func,当你调用contextor(*args,**kwargs)时将使用args、kwargs和func来初始化构造一个_GeneratorContextManager类实例,姑且记作c,具体的,在其初始化函数__init__()中会执行func(*args,**keargs)得到一个生成器对象,并保存为实例属性,姑且记作c.g,配合with使用时(with contextor(*args,**kwargs) as var),将自动调用c的__enter__()方法,而__enter__()的实现即是执行return c.g.__next__(),换句话说,上述生成器函数中yield之前的语句块1将作为上下文管理器的__enter__()方法定义,且yield表达式值将赋给变量var,当离开with语句块,将自动调用c的__exit__()方法,而__exit__()的实现即是再一次调用c.g.__next__(),换句话说,yield之后的语句块2将作为上下文管理器的__exit__()方法定义,另外,由于with语句块内部可能引发异常,异常将被c的__exit__()方法接收,默认下c.__exit__()返回False,即异常将被抛给with的外层,如果你不想抛出异常,则需要在上述生成器函数的yield位置处捕捉,因为c.__exit__()中会在存在异常的情况下,调用生成器对象的throw()方法,具体的,执行c.g.throw(type,value,traceback),该方法会在yield位置处抛出参数所指异常,如果你手动捕捉了异常,程序会继续向下执行一次生成器的next()方法,即执行语句块2,否则意味着用户定义的上下文管理器的退出方法不会被调用,这一点千万注意。不管何种情况,我们总是应该将语句块2写在finally中,并通过是否写except来决定是否将异常抛到with语句块外
1 | #示例1(来自文献[1]-p73) |
一般格式为assert expression[, msg],其中expression为False时,将触发AssertionError异常,msg是可选的自定义错误消息,注意assert不应用于必须执行以确保程序正确的代码,因为如果python运行在最优模式(通过对解释器使用-O选项进入该模式),断言语句将不会执行,那么何时使用assert呢?assert语句用于检查应该始终为真的内容
函数式编程
函数定义使用def关键字(另外可以使用lambda关键字创建表达式形式的匿名函数,形如lambda *args, **kwargs : expression),通常函数的第一条语句会使用文档字符串来描述函数的用途,可以在查看函数帮助时获取到该文档(help(func)),譬如:
1 | def f(): |
函数作为对象也具有属性,譬如上述文档字符串就存储于函数对象的__doc__属性中,函数名存储在__name__属性中,事实上,可以给函数对象绑定任意属性,这些新增属性保存在函数对象的__dict__属性中,要查看对象的所有属性,则使用dir(obj)函数,或者通过getattr(obj,attr)获取对象的指定属性(另hasattr(obj,attr)检查对象是否具有名为attr的属性,setattr(obj,attr,value)为对象设置属性),函数都是可调用的(callable(func)返回True)
1 | class A: pass |
要调用函数,只要使用函数名加上用圆括号括起来的参数即可(函数名和括号之间允许有空格),python中函数传参的形式主要有五种,分别为位置传递、关键字传递、默认传递、包裹传递和解包裹传递(后两种在前一章节已经说过了,就不重复了),看示例:
1 | #位置传递 |
若按照参数类型划分,则可分为位置参数、默认参数、可变参数和命名关键字参数,其中默认参数又分为默认位置参数和默认关键字参数(且只有命名关键字参数可以有默认值,其他关键字参数没有或者说没法设置默认值),可变(长)参数又分为可变元组参数和可变关键字参数(或可变字典参数),这里只单说一下“命名关键字参数”,函数参数定义中位于*或*args(可变元组参数)之后以及可变关键字参数之前(假设存在的话)的就是命名关键字参数,在调用时其必须具名传递,命名关键字参数可以有默认值,也可以没有,譬如:
1 | def f3(x,*,y=1,z): #x为位置参数,y和z是命名关键字参数,前者有默认值 |
不同类型参数的组合使用(定义和调用时注意顺序,基本原则是,位置参数在前,关键字参数在后):
1 | #示例1 |
在编程时,尽量避免传递可变对象(如列表、字典等),因为在函数内部对可变对象的修改将反映在原始对象中,若无法避免,则应在函数中使用可变对象的拷贝,另外函数可以不显式写return语句,在运行结束时候,会默认返回None
关于函数的作用域问题(lambda表达式遵循与函数相同的作用域规则),python中只有函数、类、模块会产生作用域(在作用域内定义的变量仅此作用域可见,但注意不同的作用域可能是包含关系,如全局作用域的范围包含局部作用域,全局作用域定义的变量在局部作用域也可访问),代码块不会产生作用域(如for循环变量会直接覆写外部的同名变量,或者说for循环变量可以在外部使用,而不仅限于for循环内部),每执行一个函数,就会创建新的局部命名空间,包含了函数参数名称和在函数体内定义的变量名称,在函数内访问变量首先会在局部空间中查找,找不到再去全局空间查找,具体的,python中有四种作用域:Local(局部作用域)、Enclosing(嵌套作用域)、Global(全局作用域)、Built-in(内置作用域),且变量的查找遵循“LEGB”规则,以内层嵌套函数为例,其首先搜索自己的局部命名空间,没有找到将由内而外在外层函数的局部命名空间中一层层地寻找(因为可以多层函数嵌套),仍没有找到,才会到全局命名空间和内置命名空间查找,如果还没有,则引发NameError异常
可以在函数内部使用global关键字将(局部)变量动态声明为全局变量,使其位于全局命名空间,影响全局作用域,如:
1 | def f(): |
类似的,对于嵌套函数,尽管它可以访问到嵌套作用域中的变量,一旦尝试对其执行如赋值等操作(如果是可变对象,则可以修改之,且无需声明nonlocal),实际会在嵌套函数的局部命名空间中新建一个同名变量,python3提供了nonlocal关键字,该声明会将名称动态绑定为外层函数中首次访问到的同名变量(多层嵌套时,可能多个外层函数都定义了同一变量,具体绑定哪个就看谁最靠内最先被访问到),于是可以在嵌套函数中修改并体现在外层,譬如:
1 | def f(): |
变量必须先赋值或定义才能使用:
1 | i=3 |
函数作为第一类对象(所谓第一类对象的特性是,对象可以赋值给变量、对象可以被当做参数传递、对象可以被当做函数的返回值返回、对象可以作为元素被添加到容器类型中),在下面的例子中,函数接受另一个函数作为输入并调用它:
1 | #定义于文件foo.py,示例来自文献[1]-p79 |
下面的例子使用了上述函数:
1 | import foo |
注意helloworld()使用的x的值是在与它相同的环境中定义的,事实上,解释器会将函数及其所在执行环境整个打包在一起,得到的函数对象称为“闭包函数”,每个函数都拥有一个指向定义该函数的全局命名空间的__globals__属性,对于嵌套函数,闭包同样将捕捉嵌套函数执行所需的整个环境,因此除了__globals__属性,还有一个指向定义该函数的嵌套作用域空间的__closure__属性,示例如下:
1 | def greeting_conf(prefix): |
在开发过程中很可能需要对一些已有的函数进行改进,假设有一个用户注册函数register(),需要提交手机号码、用户名和注册邮箱信息,其中手机号码是数据库主键,具有唯一性,有天上司要求用户名也必须唯一,出于某些原因还不能破坏原有代码,怎么办?使用装饰器可以轻松完成这一工作,只需要编写一个检测是否存在相同用户名的装饰器函数if_unique_username(),然后在原有的register()函数定义前添加一行语句@if_unique_username就ok了,等价于执行register=if_unique_username(register),@就是简化该操作的语法糖:
1 | def if_unique_username(func): #装饰器函数 |
有时候被装饰函数带有多种类型参数,譬如上述示例中装饰器if_unique_username()内层函数也需要定义和被装饰函数register一模一样的参数,其实没必要这样麻烦,可以用(*args,**kwargs)参数组合来接收任意数量的位置或关键字参数,因此实现一个通用装饰器如下:
1 | def decorator(func): |
由于数据量太大,上司决定将用户数据分地区存储在不同的数据库里,在登陆的时候根据用户的所在地来选择相应的数据库,我们希望能够给装饰器指定不同的(地区)参数,最终效果大概是:
1 | #等同于执行:register=select_database(area='江苏')(register) |
依据装饰器的原理,该功能其实不难实现,只需要定义一个三层嵌套的装饰器函数:
1 | def select_database(area): |
实际上,我们可以堆砌多个装饰器(装饰器链):
1 |
|
现在有一个问题,假设你查看经过修饰后的register()函数文档register.__doc__,会输出DOC: 选择地区数据库函数,这不符合预期,但是原因也很明显,变量名称register最终已实际指向select_database()中的内层嵌套函数_2(),解决这个问题也很容易,只要改一下_2()的函数文档就好了,于是在_2()函数定义后写一句_2.__doc__=func.__doc__、同时在if_unique_username()中的内层嵌套函数_()定义后写一句_.__doc__=func.__doc__即可,当然不只是__doc__属性,__name__等函数属性也发生了变化,另外,上述操作还可以通过装饰器来实现以简化调用(见下我自定义的wraps()函数,然后分别在_2()函数和_()函数定义上方写上一句@wraps(func)即可):
1 | def wraps(foo): |
不过标准的解决方案还是调用functools模块的@wraps装饰器,用法同上,官方实现如下(借助偏函数):
1 | WRAPPER_ASSIGNMENTS = ('__module__', '__name__', '__qualname__', '__doc__', '__annotations__') |
根据上述源码,除了使用@wraps修饰外,还有一种用法(直接调用update_wrapper()函数):
1 | from functools import update_wrapper |
另外还可以通过foo=foo.__wrapped__方便地将被装饰函数恢复为原函数(即“解除装饰器”),如果没有使用@functools.wraps,那么__wrapped__属性是不可获得的,需要注意的是,这仅仅适用于单个装饰器的情况,假设你堆砌了多个装饰函数,那么访问__wrapped__属性获取到的就不再是原函数了:
1 | from functools import wraps |
要想实现多层装饰器的解除,可以稍稍修改update_wrapper()函数源码:
1 | def update_wrapper(wrapper, |
如果不想修改源码,可以这样改:
1 | from functools import wraps |
代码很简单,缺点是代码重复编写,此处我再给出一种解决方案💡:
1 | from functools import wraps |
除了使用三层嵌套函数实现带参数的装饰器,还可以借助偏函数实现,仍以选择地区数据库注册用户为例:
1 | from functools import wraps,partial |
网上看到一种通过类实现带参装饰器的方法,核心是借助于特殊函数__call__()使类实例变得可调用,此时上述案例可以这样写:
1 | class select_database3: |
不带参数的通用的基于类实现的装饰器:
1 | from functools import update_wrapper |
最后再看几个装饰器实现的案例,一是@singledispatch,被@singledispatch装饰的普通函数会变为泛函数,即根据第一个参数的类型以不同方式执行重载函数,称为单分派(而根据多个参数选择指定的函数,称为多分派,顾名思义singledispatch是单分派),如下:
1 | from functools import singledispatch |
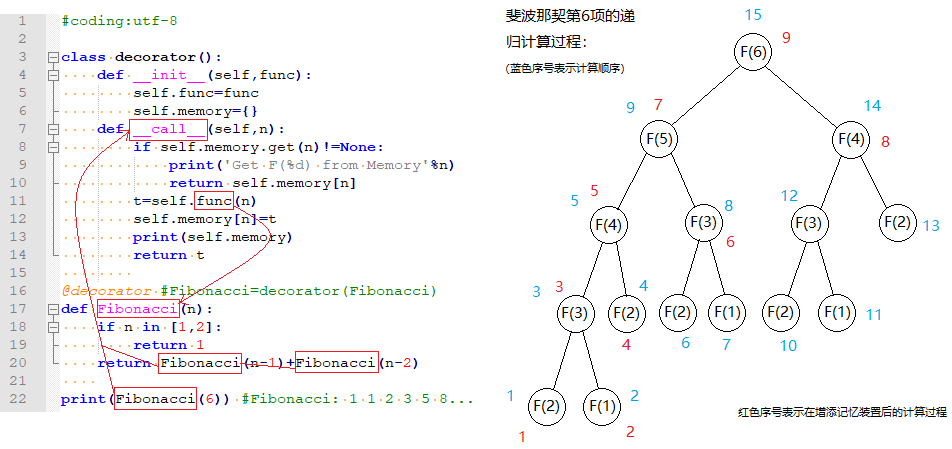
二是带记忆装置的斐波那契数项计算,上一章我们讨论过了使用递归计算斐波那契数项的问题,代码很容易理解,但是性能却十分差,要改进它,一个合理的想法是为其配备“记忆装置”,对于计算过了的值我们直接从中获取以免重复计算造成资源浪费,利用装饰器我们不需要破坏原有代码,十分优美:
1 | def memory(func): |
1 | def addLength(oldcls): |
还是以用户注册功能函数register()为例,设其接收两个参数,用户所属国家country和姓名name,对于某一地区,绝大部分人的国家属性相同,那么理应给country参数设置一个默认值,从而简化调用,具体的,定义一个参数配置函数configure(),接收原函数register地址和要设置的参数country值,并返回一个闭包函数(称为原函数的“偏函数”),当调用此闭包函数时,只需要再传入剩下的name参数,闭包函数内部会根据之前保存的country参数和刚传入的name参数去执行原函数register()实现用户注册
1 | def register(country,name): |
通用的配置函数形式:
1 | def configure(func,*args1,**kwargs1): |
所谓偏函数(或者翻译成局部应用),即是固定住原函数的部分参数(设为k个),以实现简化调用的目的(设原函数共有n个参数,局部应用将一个n元函数转换成一个n-k元函数),另有一个概念叫做“柯里化”,是一种将接受多个参数的函数转变成接受一个单一参数的函数,并且返回接受余下的参数且返回结果的新函数的技术(柯里化将一个n元函数转换成n个一元函数),可能不太好理解,直接看示例,一个实现三个数相加的加法操作:
1 | def add(a,b,c): |
其柯里化版本为:
1 | def add(a): |
显然,我们不可能每次都花这么大的功夫为一个函数特别定制其柯里化版本,为此,定义了一个转换函数curry(),能够接收一个函数对象作为参数,并将其转换为柯里化版本:
1 | #这是一个更具通用性的curry(),随后你除了可以这样调用add(1)(2)(3),还可以add(1)(2,3)或add(1,2)(3) |
除了上述通用的配置函数实现,我在PEP文档中找到了一个利用__call__()实现的类版本:
1 | class partial(object): |
最后要说的是,python中实现偏函数的标准方法是通过from functools import partial,另外,除了为函数预设部分参数值构成偏函数,实际上任何可以通过()调用的都可以进行“偏应用”,譬如类、类实例、类/实例方法都可以通过()调用:
1 | from functools import partial |
在函数内,yield语句还可以用作出现在赋值运算右边的表达式,例如:
1 | def receiver(): |
以这种方式使用yield语句的函数称为“协程”(协程反映了程序逻辑的一种需求:可重入(子程序/函数的)能力。协程能保留上一次调用时的状态,每次重入时,就相当于进入上一次调用的状态),它的执行是为了响应发送给它的值,其行为也类似于生成器:
1 | r=receiver() #此时函数尚未执行 |
上述示例中在执行发送前需要先调用一次next()方法,不太方便,可以定义一个装饰器以自动调用:
1 | def coroutine(func): |
协程的运行一般是无限期的,除非它被显式关闭(调用close()方法)或者自己退出,关闭后如果继续给协程发送值,将会引发StopIteration异常,正如之前在关于生成器的内容中所讲,close()操作将会在协程内部yield位置处引发GenaratorExit异常,你可以选择捕捉它。另外调用throw(exctype[,value[,tb]])方法也会在协程内部yield位置处引发异常,异常的类型、值和跟踪对象分别由exctype、value和tb参数指定
如果赋值号右边的yield语句本身含有表达式(不同于上面的var=yield,而是var=yield expression的形式),这个表达式的值将作为send()方法的返回值,此时协程可以使用yield语句同时接收和发出返回值,下面看一个生产者和消费者的示例:
1 | import time |
需要注意的是,最开始的next()调用只会执行到赋值号右边的(yield [expression])处(且直到执行send()时才会完成赋值),并返回yield中的表达式expression值,在接下来的send()调用中,协程将从暂停处继起,直到再次遇到(yield [expression])暂停,并将此时计算得到的expression作为send()方法的返回值
列表生成式
1
2
3
4
5ret=[x * x for x in range(10)]
ret
[0, 1, 4, 9, 16, 25, 36, 49, 64, 81]
type(_)
<class 'list'>集合生成式
1
2
3
4
5ret={x * x for x in [-5,-3,-1,1,3,5]}
ret
{25, 9, 1}
type(_)
<class 'set'>字典生成式
1
2
3
4
5ret={x:x for x in range(5)}
ret
{0: 0, 1: 1, 2: 2, 3: 3, 4: 4}
type(_)
<class 'dict'>生成器表达式
和列表生成式几乎一样,只不过将中括号
[]替换成()即可,返回的是生成器对象
注1,以上所有的生成式都支持多重for循环,如:[(i,j,k) for i in range(4) for j in range(3) for k in range(2)](注意for循环的顺序是从左至右的,即左边for循环的迭代变量可以出现在右边for循环中但是反之不可以),譬如:
1 | ret=((x,y) for x in range(5) for y in range(x)) |
注2,以上所有的生成式都可以搭配if条件判断(没有else),以列表生成式为例:[expression for i in iterable if condition](条件判断的作用同filter()函数,用于过滤序列中的部分元素),由于expression本身也可以是一个条件表达式,因此还可以写成:[expression1 if condition else expression2 for i in iterable],示例:
1 | [i for i in range(10) if i%3==0] #从0-9的序列中筛选出3的整数倍 |





